Overview¶
StandardE2E is a unified framework for preprocessing, indexing, and loading autonomous driving datasets. It enables training models on multiple heterogeneous datasets with a single, consistent API.
Why StandardE2E?¶
Training autonomous driving models on diverse datasets is challenging:
Different data formats: Each dataset has unique file structures and APIs
Inconsistent modalities: Camera formats, LiDAR representations, and annotation styles vary
Complex preprocessing: Converting raw data to model-ready format requires dataset-specific code
Limited flexibility: Switching or combining datasets means rewriting data pipelines
StandardE2E solves these problems by providing:
- 🎯 One Format to Rule Them All
All datasets are converted to a unified
TransformedFrameDatarepresentation with consistent modality keys and metadata.- ⚡ Efficient Indexing
Parquet-based indexes enable fast filtering, sampling, and frame lookup without loading heavy scene data.
- 🔌 Extensible by Adding New Datasets
Once processed, new datasets follow the same API and provide consistent data structures.
- 🎨 Flexible Augmentation
Chain frame-level augmentations that work across all datasets. Regime-aware (train/val/test).
- 🔧 Parametrizable Pipelines
Configure what to load programmatically or via YAML config files. You can fetch required frames and specific modalities for each of them.
Architecture¶
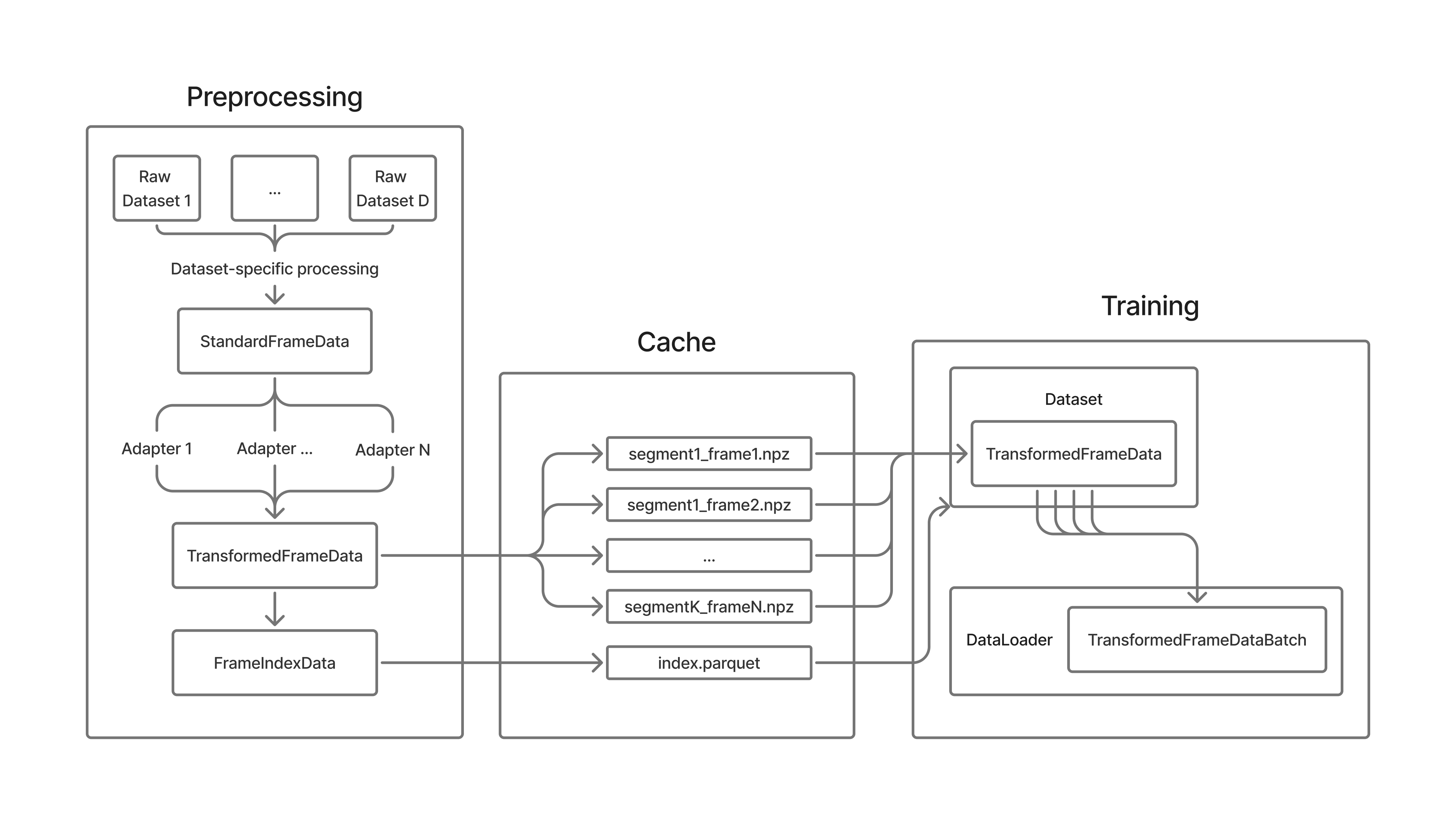
StandardE2E consists of two parts:
Preprocessing¶
Preprocessing converts raw datasets into a unified, training-ready on-disk format. It is where dataset-specific processing happens, and where reusable user-defined adapters are applied.
Preprocessing uses a two-stage data transformation:
- Raw dataset →
StandardFrameData(dataset-agnostic intermediate format) Handled by dataset-specific processors and kept free of user-defined transformations. Basically,
StandardFrameDatakeeps a raw frame data in a consistent structure. See adding_new_dataset.md to learn how to add new datasets.
- Raw dataset →
StandardFrameData→AbstractAdapter→TransformedFrameData.Adapters apply user-defined transformations (image resizing, panorama projection, normalization, etc.), making the format efficient and training-ready. See intro_tutorial.ipynb and creating_custom_adapter.ipynb to learn more about adapters.
- Processing stage also produces a Parquet index for fast frame lookup, filtering and
storing extra metadata.
- As the final stage
SegmentContextAggregatormay be applied to aggregate segment-level context into frame-level data (e.g., current position into trajectory).
- As the final stage
Training¶
Training is where you load the preprocessed data for model training or evaluation.
The main entry point is UnifiedE2EDataset,
which accepts an index table from index.parquet (or from multiple files for combined dataset) and loads frames from
disk. It also handles the following functionalities:
- Filtering the dataset with
IndexFilter, eg filtering the frames by some boolean column with
FrameFilterByBooleanColumn.
- Filtering the dataset with
- Applying regime-aware augmentations via
FrameAugmentation, eg image augmentations with
MultipleFramesImageAugmentation.
- Applying regime-aware augmentations via
- Enforcing modality defaults via
ModalityDefaults, eg providing
UNKNOWNintent when intent labels are missing withIntentDefaults.
- Enforcing modality defaults via